Author
- Guillaume Lample, Alexis Conneau
Abstract
- 2가지 Cross-lingual LM(XLM)을 제시
- 단일 언어 말뭉치에 대한 비지도학습 방법
- 두개 언어에 대해 병렬 말뭉치가 있을 때 지도학습 방법
- 그리고 이것은 매우 좋은 성능을 보였음.
1. Introduction
- 트랜스포머 이후에 많은 LM기반 Pre-Training모델들이 나왔지만, 대부분 하나의 언어(특히 영어)에 포커스 된 형태.
- 최근 이러한 영어 중심의 바이어스된 문제를 완화하고 싶음.
- 방안으로 여러 언어가 하나의 임베딩 공간을 공유하고 어떤 언어로 쓰인 문장도 해당 임베딩 공간으로 인코딩 되도록 하는 유니버셜 인코더를 만들고자 함.
- 결국, 하고자 하는 것 : we demonstrate the effectiveness of cross-lingual language model pretraining on multiple cross-lingual understanding (XLU) benchmarks
- 새로운 비지도 학습 방법 제시
- 병렬 데이터를 이용한 지도 학습 방법 제시
- 성능 확인 : previous state of the art on cross-lingual classification, unsupervised machine translation and supervised machine
- 오픈 할꺼임
3. Cross-lingual language model
2개의 단일언어 기반 비지도 학습법, 1개의 병렬 말뭉치 기반 지도 학습
3.1 Shared sub-word vocabulary
- 기본적으로 BPE사용
- 언어간 같은 단어(숫자나 고유명사 등)은 공유
-
문장들은 monolingual corpora에서 일정 확률 분포를 이용해서 추출(a = 0.5)
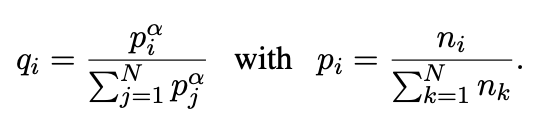
3.2 Causal Language Modeling(CLM)
-
일반적인 Transformer Decoder를 이용한 LM

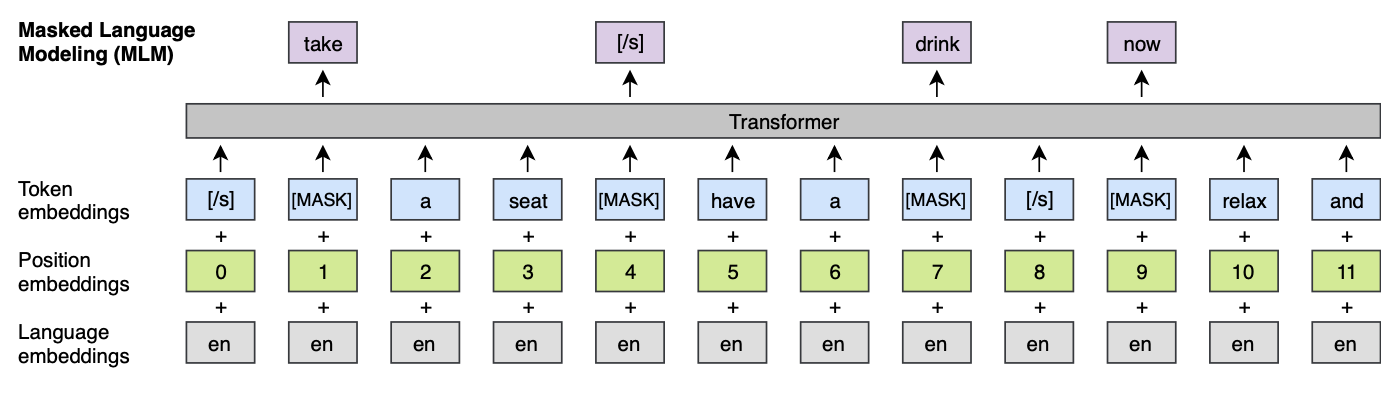
3.3 Masked Language Modeling(MLM)
-
BERT와 같은 형태
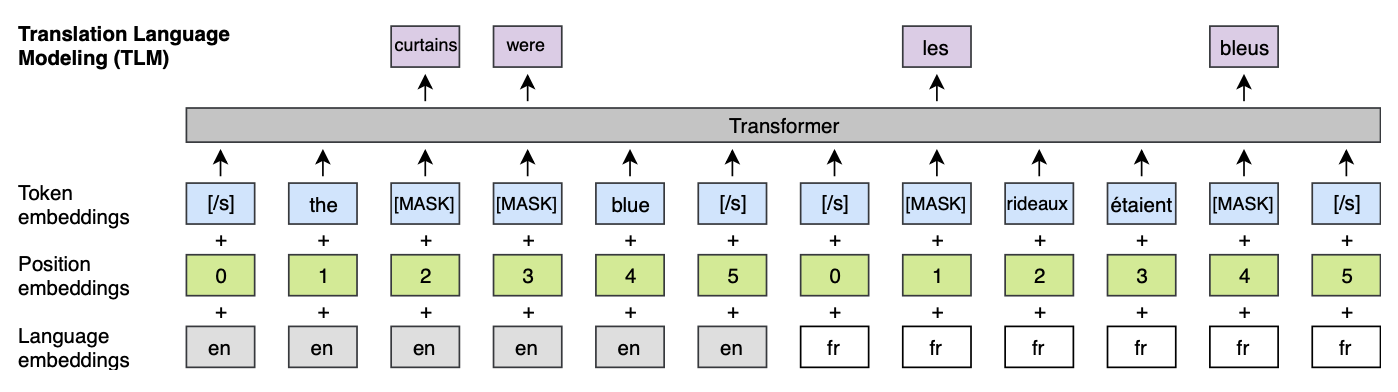
3.4 Translation Language Modeling(TLM)
- 번역 말뭉치에서 원본 문장과 번역 문장을 이용 (같은 의미를 가지는 언어가 다른 두 개의 문장 : Source lang, Target lang)
- 각 문장의 Position Embedding은 각각 문장 시작점을 ‘0’으로 함
-
그리고 전체 문장에 Mask를 씌움
3.5 Cross-lingual Language Models
- 3개의 방법으로 pretraining 진행 : CLM, MLM, CLM used in combination with TML
- CLM, MLM
- Batch size : 64
- Token length : 256
- 같은 배치 내에서는 같은 언어만
- CLM used in combination with TML
- 같은 배치내에서는 같은 언어쌍이 나오도록 함
4. Cross-lingual language model pretraining
- Cross-lingual LM 를 통해 얻고자 하는 것
- a better initialization of sentence encoders for zero-shot cross-lingual classification
- a better initialization of supervised and unsupervised neural machine translation systems
- language models for low-resource languages
- unsupervised cross-lingual word embeddings
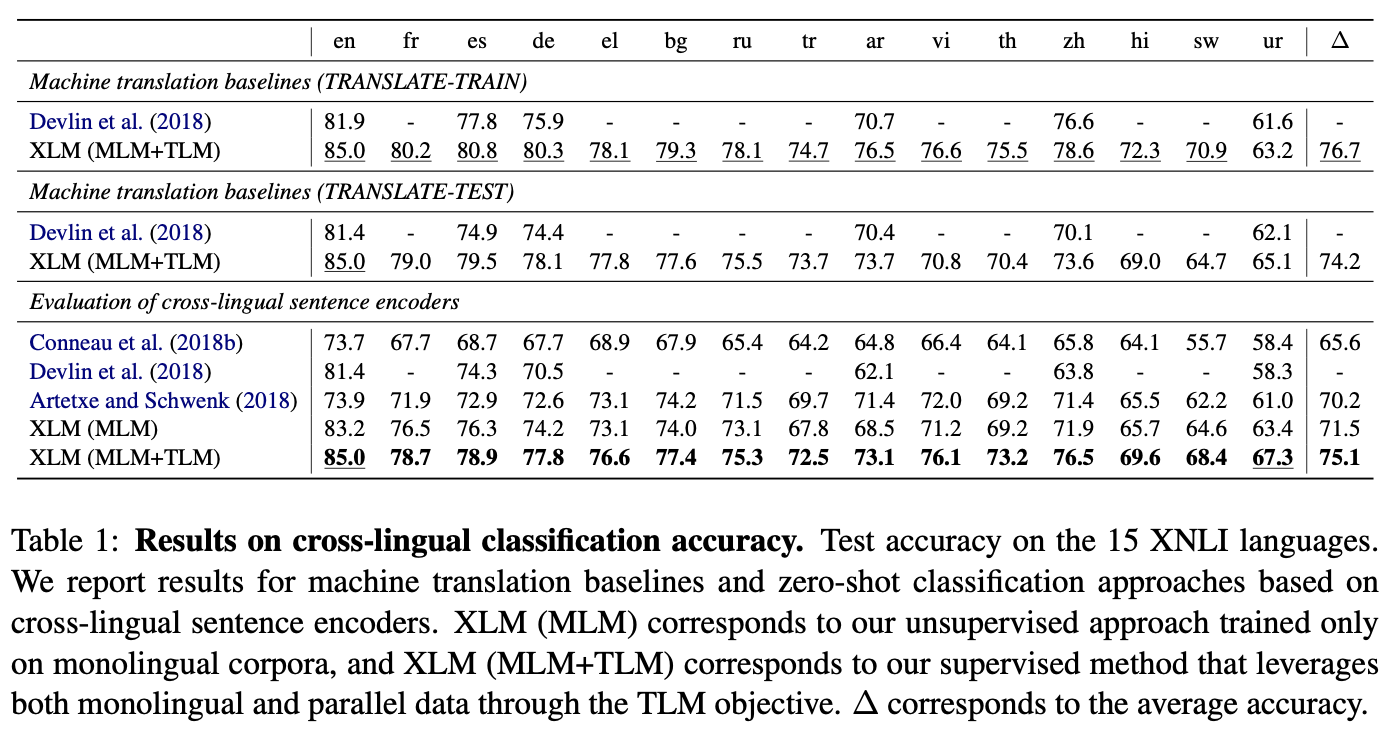
4.1 Cross-lingual classification
- “Cross-lingual natural language inference (XNLI) dataset”을 성능 측정을 위해 사용할 예정
- Pre-training 이후에 Transformer 뒷단에 linear classifer 하나를 두고 영어 NLI 학습 셋으로 fine-tuning 진행
- 그 후에 15개 언어에 대해 XNLI를 테스트
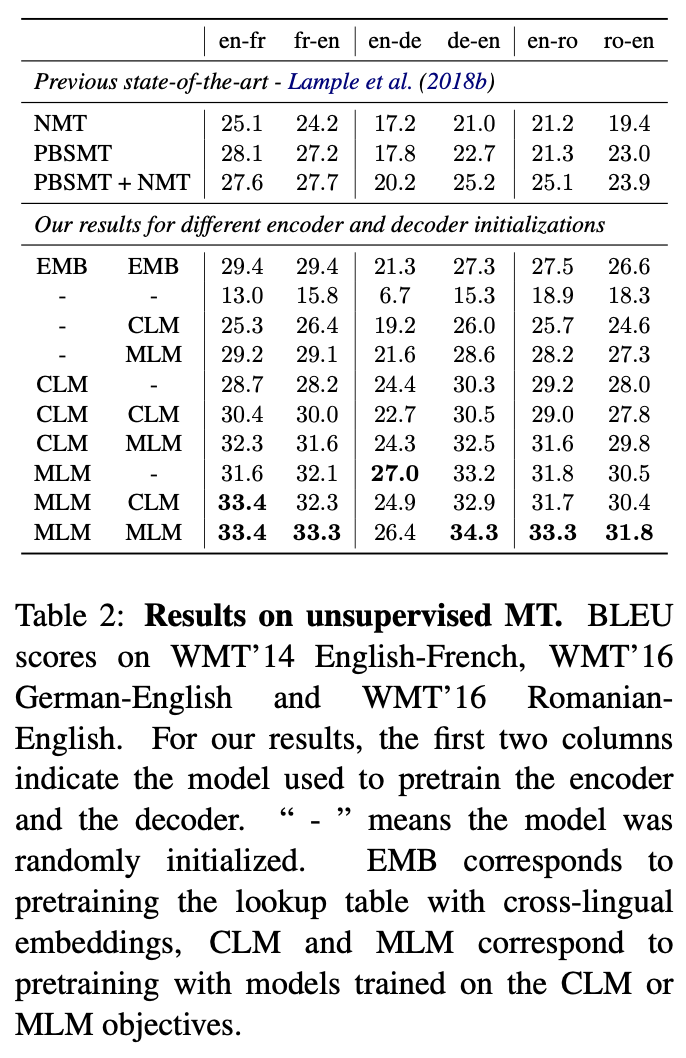
4.2 Unsupervised Machine Translation
- “Unsupervised neural machine translation(UNMT)” 에서 초기 cross-lingual word embedding의 품질이 매우 중요함.
- 초기 word-embedding을 룩업 테이블을 사용하는 대신 Transformer Encoder-Decoder를 Cross-Lingual LM 방법으로 학습해서 사용.
- “WMT 14 En-Fr”, “WMT 16 En-Dr”, “WMT 16 En - Ro” 에 대해 테스트
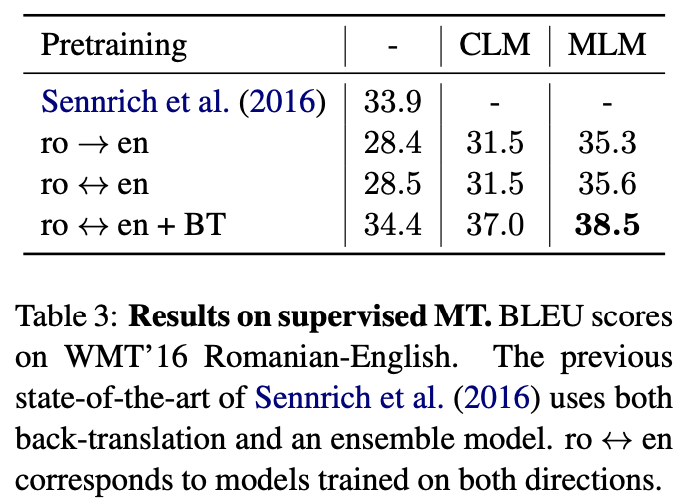
4.3 Supervised Machine Translation
- “WMT 16 En-Ro” 로 테스트
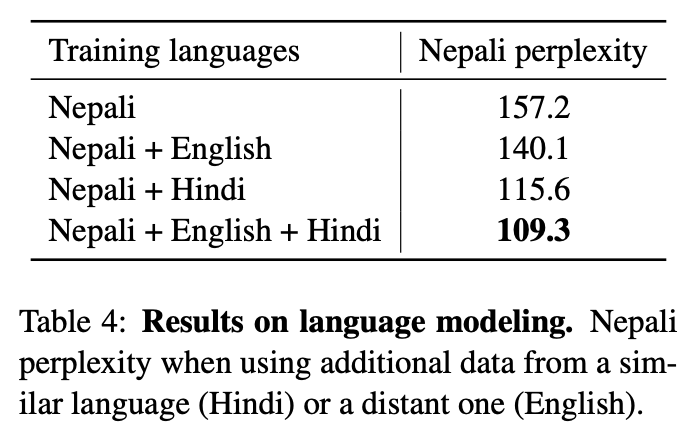
4.4 Low-resource language modeling
- Wikipedia에 100k 문장 정도의 네팔어가 있고 힌디어는 약 6배 정도 됨
- 두 개의 언어는 약 80% 정도의 BPE vocab을 공유(100k subword units)
- 이 경우, 네팔어만 가지고 LM을 한 것과, 힌디어를 함께 한것, 또 영어까지 함께 한 것을 가지고 비교
- 비교 방법은 LM에서 perplexiy 측정
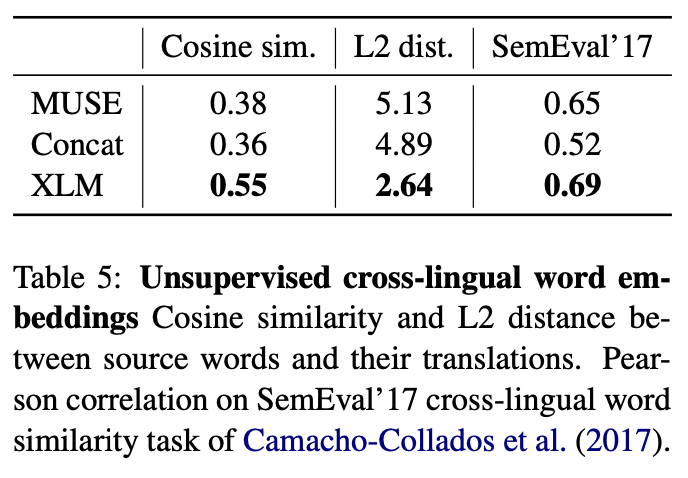
4.5 Unsupervised cross-lingual word embedding
- 3가지 방법을 비교
-
“Word translation without parallel data” 방법
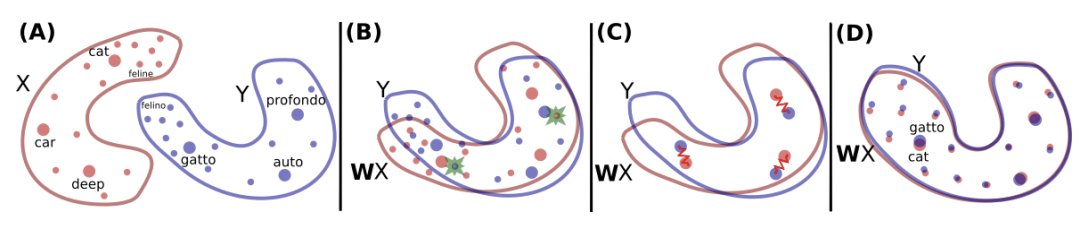
- Shared Vocab을 만들고 fastText 방법으로 Embedding 학습(common alphabet 이용)
- XLM에서 단어를 그대로 룩업해서 사용
-
- 비교 방법 : cosine similarity, L2 distance, cross-lingual word similarity
5. Experiments and results